As part of my role the Python advocacy team for Azure, I am now one of the maintainers on several ChatGPT samples, like my simple chat app and this popular chat + search app. In this series of blog posts, I'll share my learnings for writing chat-like applications. My experience is from apps with Python backends, but many of these practices apply cross-language.
My first tip is to use an asynchronous backend framework so that your app is capable of fulfilling concurrent requests from users.
The need for concurrency
Why? Let's imagine that we used a synchronous framework, like Flask. We deploy that to a server using gunicorn and several workers. One of those workers receives a POST request to the "/chat" endpoint. That chat endpoint in turns makes a request to the Azure ChatCompletions API. The request can take a while to complete - several seconds! During that time, the worker is tied up and cannot handle any more user requests. We could throw more CPUs and thus workers and threads at the problem, but that's a waste of server resources.
Without concurrency, requests must be handled serially:

The better approach when our app has long blocking I/O calls is to use an asynchronous framework. That way, when a request has gone out to a potentially slow-to-respond API, the Python program can pause that coroutine and handle a brand new request.
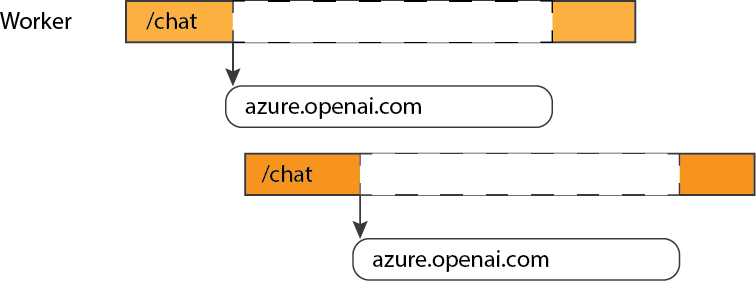
With concurrency, workers can handle new requests during I/O calls:
Asynchronous Python backends
We use Quart, the asynchronous version of Flask, for the simple chat quickstart as well as the chat + search app. I've also ported the simple chat to FastAPI, the most popular asynchronous framework for Python.
Our handlers now all have async in front, signifying that they return a Python coroutine instead of a normal function:
async def chat_handler():
request_message = (await request.get_json())["message"]
When we deploy those apps, we still use gunicorn, but with the uvicorn worker, which is designed for Python ASGI apps. The gunicorn.conf.py configures it like so:
num_cpus = multiprocessing.cpu_count()
workers = (num_cpus * 2) + 1
worker_class = "uvicorn.workers.UvicornWorker"
Asynchronous API calls
To really benefit from the port to an asynchronous framework, we need to make asynchronous calls to all of the APIs, so that a worker can handle a new request whenever an API call is being awaited.
First, we must use an async version of the OpenAI constructor, either AsyncOpenAI or AsyncAzureOpenAI:
openai_client = openai.AsyncAzureOpenAI(
azure_endpoint=os.environ["AZURE_OPENAI_ENDPOINT"],
api_version=os.environ["AZURE_OPENAI_API_VERSION"],
azure_ad_token_provider=token_provider
)Then, whenever we make API calls with methods on that client, we await their results:
chat_coroutine = await openai_client.chat.completions.create(
deployment_id=os.environ["AZURE_OPENAI_CHAT_DEPLOYMENT"],
messages=[{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": request_message}],
stream=True,
)
For the RAG sample, we also have calls to Azure services like Azure Cognitive Search. To make those asynchronous, we first import the async variant of the credential and client classes in the aio module:
from azure.identity.aio import DefaultAzureCredential
from azure.search.documents.aio import SearchClient
Then, like with the openai async clients, we must await results from any methods that make network calls:
r = await self.search_client.search(query_text)
No comments:
Post a Comment