When we’re programming user-facing experiences, we want to feel confident that we’re creating a functional user experience - not a broken one! How do we do that? We write tests, like unit tests, integration tests, smoke tests, accessibility tests, loadtests, property-based tests. We can’t automate all forms of testing, so we test what we can, and hire humans to audit what we can’t.
But when we’re building RAG chat apps built on LLMs, we need to introduce an entirely new form of testing to give us confidence that our LLM responses are coherent, grounded, and well-formed.
We call this form of testing “evaluation”, and we can now automate it with the help of the most powerful LLM in town: GPT-4.
How to evaluate a RAG chat app
The general approach is:
- Generate a set of “ground truth” data- at least 200 question-answer pairs. We can use an LLM to generate that data, but it’s best to have humans review it and update continually based on real usage examples.
- For each question, pose the question to your chat app and record the answer and context (data chunks used).
- Send the ground truth data with the newly recorded data to GPT-4 and prompt it to evaluate its quality, rating answers on 1-5 scales for each metric. This step involves careful prompt engineering and experimentation.
- Record the ratings for each question, compute average ratings and overall pass rates, and compare to previous runs.
- If your statistics are better or equal to previous runs, then you can feel fairly confident that your chat experience has not regressed.
Evaluate using the Azure AI Generative SDK
A team of ML experts at Azure have put together an SDK to run evaluations on chat apps, in the azure-ai-generative Python package. The key functions are:
QADataGenerator.generate(text, qa_type, num_questions): Pass a document, and it will use a configured GPT-4 model to generate multiple Q/A pairs based on it.evaluate(target, data, data_mapping, metrics_list, ...): Point this function at a chat app function and ground truth data, configure what metrics you’re interested in, and it will aak GPT-4 to rate the answers.
Start with this evaluation project template
Since I've been spending a lot of time maintaining our most popular RAG chat app solution, I wanted to make it easy to test changes to that app's base configuration - but also make it easy for any developers to test changes to their own RAG chat apps. So I've put together ai-rag-chat-evaluator, a repository with command-line tools for generating data, evaluating apps (local or deployed), and reviewing the results.
For example, after configuring an OpenAI connection and Azure AI Search connection, generate data with this command:
python3 -m scripts generate --output=example_input/qa.jsonl --numquestions=200To run an evaluation against ground truth data, run this command:
python3 -m scripts evaluate --config=example_config.jsonYou'll then be able to view a summary of results with the summary tool:
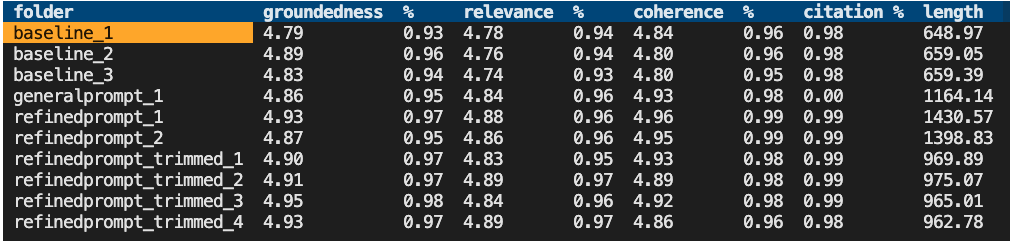
You'll also be able to easily compare answers across runs with the compare tool:
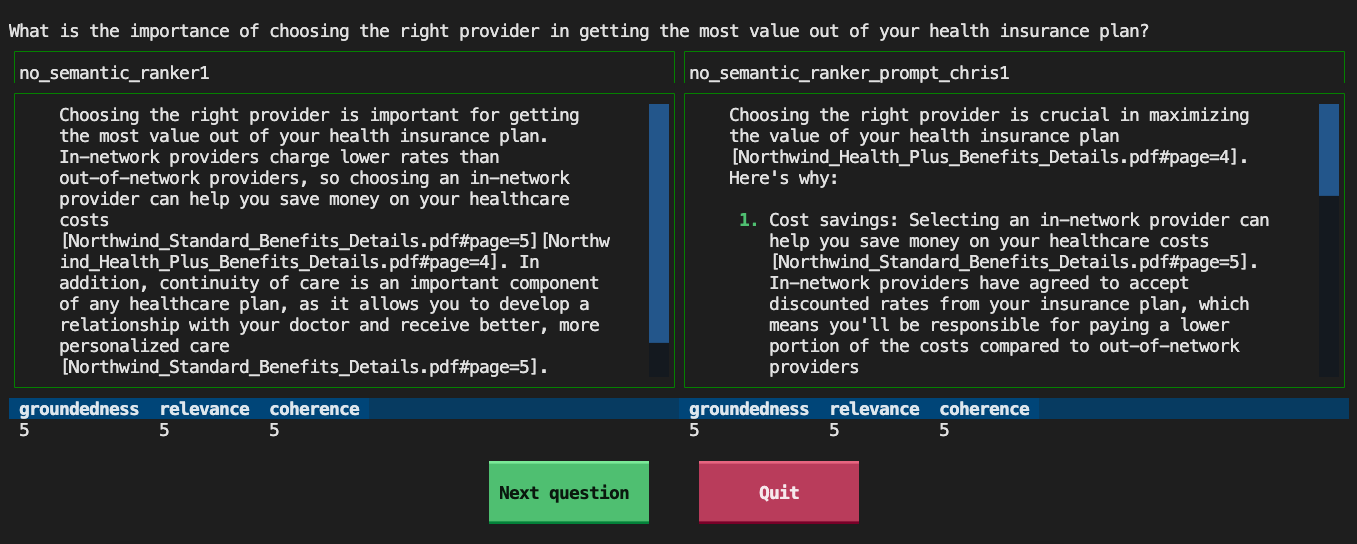
For more details on using the project, check the README and please file an issue with any questions, concerns, or bug reports.
When to run evaluation tests
This evaluation process isn’t like other automated testing that a CI would runs on every commit, as it is too time-intensive and costly.
Instead, RAG development teams should run an evaluation flow when something has changed about the RAG flow itself, like the system message, LLM parameters, or search parameters.
Here is one possible workflow:
- A developer tests a modification of the RAG prompt and runs the evaluation on their local machine, against a locally running app, and compares to an evaluation for the previous state ("baseline").
- That developer makes a PR to the app repository with their prompt change.
- A CI action notices that the prompt has changed, and adds a comment requiring the developer to point to their evaluation results, or possibly copy them into the repo into a specified folder.
- The CI action could confirm the evaluation results exceed or are equal to the current statistics, and mark the PR as mergeable. (It could also run the evaluation itself at this point, but I'm wary of recommending running expensive evaluations twice).
- After any changes are merged, the development team could use an A/B or canary test alongside feedback buttons (thumbs up/down) to make sure that the chat app is working as well as expected.
I'd love to hear how RAG chat app development teams are running their evaluation flows, to see how we can help in providing reusable tools for all of you. Please let us know!
No comments:
Post a Comment