I'm concerned by the number of times I've heard, "oh, we can do RAG with retriever X, here's the vector search query." Yes, your retriever for a RAG flow should definitely support vector search, since that will let you find documents with similar semantics to a user's query, but vector search is not enough. Your retriever should support a full hybrid search, meaning that it can perform both a vector search and full text search, then merge and re-rank the results. That will allow your RAG flow to find both semantically similar concepts, but also find exact matches like proper names, IDs, and numbers.
Hybrid search steps
Azure AI Search offers a full hybrid search with all those components:
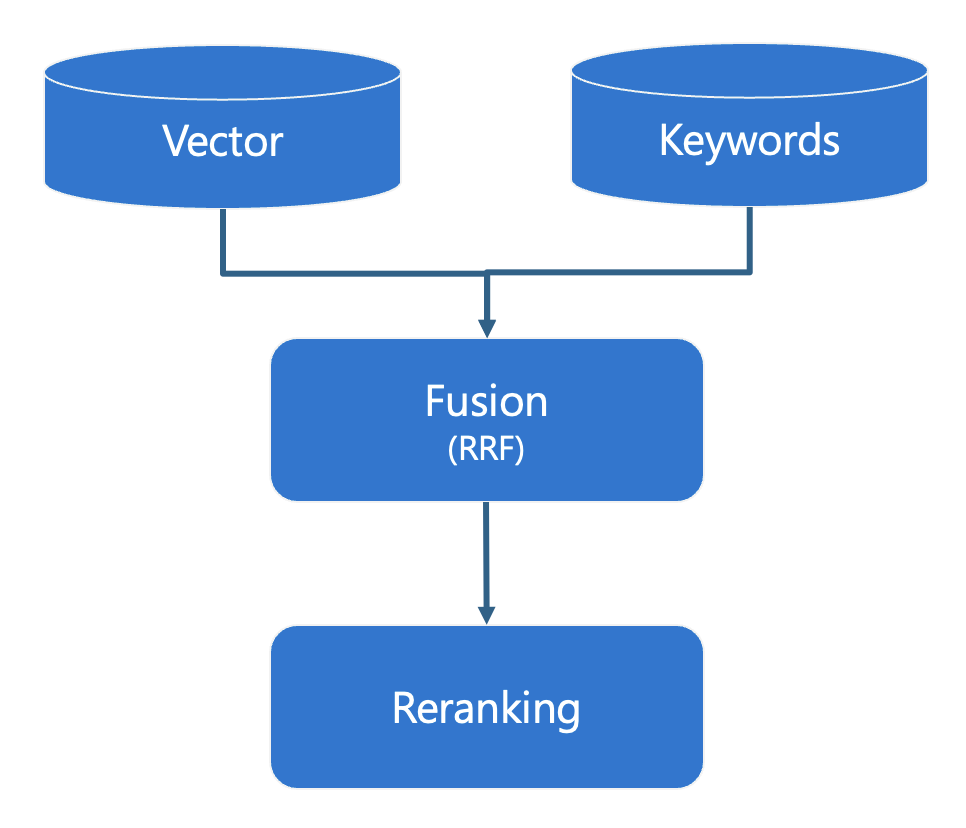
- It performs a vector search using a distance metric (typically cosine or dot product).
- It performs a full-text search using the BM25 scoring algorithm.
- It merges the results using Reciprocal Rank Fusion algorithm.
- It re-ranks the results using semantic ranker, a machine learning model used by Bing, that compares each result to the original usery query and assigns a score from 0-4.
The search team even researched all the options against a standard dataset, and wrote a blog post comparing the retrieval results for full text search only, vector search only, hybrid search only, and hybrid plus ranker. Unsurprisingly, they found that the best results came from using the full stack, and that's why it's the default configuration we use in the AI Search RAG starter app.
When is hybrid search needed?
To demonstrate the importance of going beyond vector search, I'll show some queries based off the sample documents in the AI Search RAG starter app. Those documents are from a fictional company and discuss internal policies like healthcare and benefits.
Let's start by searching "what plan costs $45.00?" with a pure vector search using an AI Search index:
search_query = "what plan costs $45.00"
search_vector = get_embedding(search_query)
r = search_client.search(None, top=3, vector_queries=[
VectorizedQuery(search_vector, k_nearest_neighbors=50, fields="embedding")])
The results for that query contain numbers and costs, like the string "The copayment for primary care visits is typically around $20, while specialist visits have a copayment of around $50.", but none of the results contain an exact cost of $45.00, what the user was looking for.
Now let's try that query with a pure full-text search:
r = search_client.search(search_query, top=3)
The top result for that query contain a table of costs for the health insurance plans, with a row containing $45.00.
Of course, we don't want to be limited to full text queries, since many user queries would be better answered by vector search, so let's try this query with hybrid:
r = search_client.search(search_query, top=15, vector_queries=[
VectorizedQuery(search_vector, k_nearest_neighbors=10, fields="embedding")])
Once again, the top result is the table with the costs and exact string of $45.00. When the user asks that question in the context of the full RAG app, they get the answer they were hoping for:

You might think, well, how many users are searching for exact strings? Consider how often you search your email for a particular person's name, or how often you search the web for a particular programming function name. Users will make queries that are better answered by full-text search, and that's why we need hybrid search solutions.
Here's one more reason why vector search alone isn't enough: assuming you're using generic embedding models like the OpenAI models, those models are generally not a perfect fit for your domain. Their understanding of certain terms aren't going to be the same as a model that was trained entirely on your domain's data. Using hybrid search helps to compensate for the differences in the embedding domain.
When is re-ranking needed?
Now that you're hopefully convinced about hybrid search, let's talk about the final step: re-ranking results according to the original user query.
Now we'll search the same documents for "learning about underwater activities" with a hybrid search:
search_query = "learning about underwater activities"
search_vector = get_embedding(search_query)
r = search_client.search(search_query, top=5, vector_queries=[
VectorizedQuery(search_vector, k_nearest_neighbors=10, fields="embedding")])
The third result for that query contains the most relevant result, a benefits document that mentions surfing lessons and scuba diving lessons. The phrase "underwater" doesn't appear in any documents, notably, so those results are coming from the vector search component.
What happens if we add in the semantic ranker?
search_query = "learning about underwater activities"
search_vector = get_embedding(search_query)
r = search_client.search(search_query, top=5, vector_queries=[
VectorizedQuery(search_vector, k_nearest_neighbors=50, fields="embedding")],
query_type="semantic", semantic_configuration_name="default")
Now the very top result for the query is the document chunk about surfing and scuba diving lessons, since the semantic ranker realized that was the most pertinent result for the user query. When the user asks a question like that in the RAG flow, they get a correct answer with the expected citation:

Our search yielded the right result in both cases, so why should we bother with the ranker? For RAG applications, which send search results to an LLM like GPT-3.5, we typically limit the number of results to a fairly low number, like 3 or 5 results. That's due to research that shows that LLMs tend to get "lost in the middle" when too much context is thrown at them. We want those top N results to be the most relevant results, and to not contain any irrelevant results. By using the re-ranker, our top results are more likely to contain the closest matching content for the query.
Plus, there's a big additional benefit: each of the results now has a re-ranker score from 0-4, which makes it easy for us to filter out results with re-ranker scores below some threshold (like < 1.5). Remember that any search algorithm that includes vector search will always find results, even if those results aren't very close to the original query at all, since vector search just looks for the closest vectors in the entire vector space. So when your search involves vector search, you ideally want a re-ranking step and a scoring approach that will make it easier for you to discard results that just aren't relevant enough on an absolute scale.
Implementing hybrid search
As you can see from my examples, Azure AI Search can do everything we need for a RAG retrieval solution (and even more than we've covered here, like filters and custom scoring algorithms. However, you might be reading this because you're interested in using a different retriever for your RAG solution, such as a database. You should be able to implement hybrid search on top of most databases, provided they have some capability for text search and vector search.
As an example, consider the PostgreSQL database. It already has built-in full text search, and there's a popular extension called pgvector for bringing in vector indexes and distance operators. The next step is to combine them together in a hybrid search, which is demonstrated in this example from the pgvector-python repository:.
WITH semantic_search AS (
SELECT id, RANK () OVER (ORDER BY embedding <=> %(embedding)s) AS rank
FROM documents
ORDER BY embedding <=> %(embedding)s
LIMIT 20
),
keyword_search AS (
SELECT id, RANK () OVER (ORDER BY ts_rank_cd(to_tsvector('english', content), query) DESC)
FROM documents, plainto_tsquery('english', %(query)s) query
WHERE to_tsvector('english', content) @@ query
ORDER BY ts_rank_cd(to_tsvector('english', content), query) DESC
LIMIT 20
)
SELECT
COALESCE(semantic_search.id, keyword_search.id) AS id,
COALESCE(1.0 / (%(k)s + semantic_search.rank), 0.0) +
COALESCE(1.0 / (%(k)s + keyword_search.rank), 0.0) AS score
FROM semantic_search
FULL OUTER JOIN keyword_search ON semantic_search.id = keyword_search.id
ORDER BY score DESC
LIMIT 5
That SQL performs a hybrid search by running a vector search and text search and combining them together with RRF. Another example from that repo shows how we could bring in a cross-encoding model for a final re-ranking step:
encoder = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
scores = encoder.predict([(query, item[1]) for item in results])
results = [v for _, v in sorted(zip(scores, results), reverse=True)]
That code would run the cross-encoding model in the same process as the rest of the PostgreSQL query, so it could work well in a local or test environment, but it wouldn't necessarily scale well in a production environment. Ideally, a call to a cross-encoder would be made in a separate service that had access to a GPU and dedicated resources.
I have implemented the first three steps of hybrid search in a RAG-on-PostgreSQL starter app. Since I don't yet have a good way to productionize a call to a cross-encoding model, I have not brought in the final re-ranking step.
After seeing what it takes to replicate full hybrid search options on other database, I am even more appreciative of the work done by the Azure AI Search team. If you've decided that, nevermind, you'll go with Azure AI Search, check out the AI Search RAG starter app. You might also check out open source packages, such as llamaindex which has at least partial hybrid search support for a number of databases. If you've used or implemented hybrid search on a different database, please share your experience in the comments.
When in doubt, evaluate
When choosing our retriever and retriever options for RAG applications, we need to evaluate answer quality. I stepped through a few example queries above, but for a user-facing app, we really need to do bulk evaluations of a large quantity of questions (~200) to see the effect of an option on answer quality. To make it easier to run bulk evaluations, I've created the ai-rag-chat-evaluator repository, that can run both GPT-based metrics and code-based metrics against RAG chat apps.
Here are the results from evaluations against a synthetically generated data set for a RAG app based on all my personal blog posts:
| search mode | groundedness | relevance | answer_length | citation_match |
|---|---|---|---|---|
| vector only | 2.79 | 1.81 | 366.73 | 0.02 |
| text only | 4.87 | 4.74 | 662.34 | 0.89 |
| hybrid | 3.26 | 2.15 | 365.66 | 0.11 |
| hybrid with ranker | 4.89 | 4.78 | 670.89 | 0.92 |
Despite being the author of this blog post, I was shocked to see how poorly vector search did on its own, with an average groundedness of 2.79 (out of 5) and only 2% of the answers with citations matching the ground truth citations. Full-text search on its own did fairly well, with an average groundedness of 4.87 and a citation match rate of 89%. Hybrid search without the semantic ranker improved upon vector search, with an average groundedness of 3.26 and citation match of 11%, but it did much better with the semantic ranker, with an average groundedness of 4.89 and a citation match rate of 92%. As we would expect, that's the highest numbers across all the options.
But why do we see vector search and ranker-less hybrid search scoring so remarkably low? Besides what I've talked about above, I think it's also due to:
- The full-text search option in Azure AI Search is really good. It uses BM25 and is fairly battle-tested, having been around for many years before vector search became so popular. The BM25 algorithm is based off TF-IDF and produces something like sparse vectors itself, so it's more advanced than a simple substring search. AI Search also uses standard NLP tricks like stemming and spell check. Many databases have full text search capabilities, but they won't all be as full-featured as the Azure AI Search full-text search.
- My ground truth data set is biased towards compatibility with full-text-search. I generated the sample questions and answers by feeding my blog posts to GPT-4 and asking it to come up with good Q&A based off the text, so I think it's very likely that GPT-4 chose to use similar wording as my posts. An actual question-asker might use very different wording - heck, they might even ask in a different language like Spanish or Chinese! That's where vector search could really shine, and where full-text search wouldn't do so well. It's a good reminder of why need to continue updating evaluation data sets based off what our RAG chat users ask in the real world.
So in conclusion, if we are going to go down the path of using vector search, it is absolutely imperative that we employ a full hybrid search with all four steps and that we evaluate our results to ensure we're using the best retrieval options for the job.
No comments:
Post a Comment