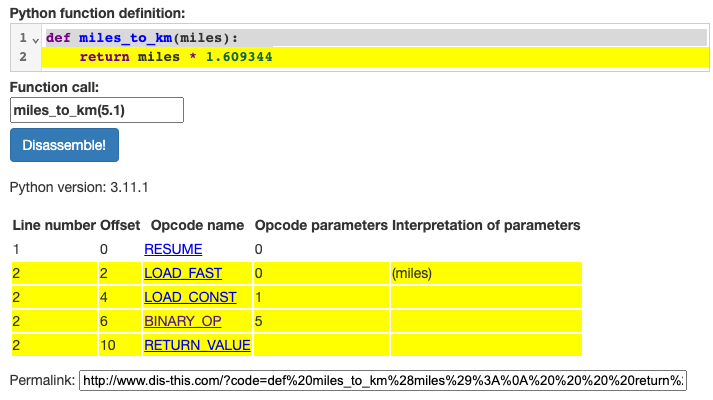
When I asked developers on Mastodon "what framework do you use for building APIs?", the two most popular answers were FastAPI and Flask. So I set out building an API using Flask to see what the experience was like. I immediately found myself wanting a library like FastAPI to handle parameter validation for me, and I discovered APIFlask, a very similar framework that's still "100% compatible with the Flask ecosystem".
The Chart API
Using APIFlask, I wrote an API to generate Chart PNGs using matplotlib, with endpoints for both bar charts and pie charts. It could easily support many other kinds of charts, but I'll leave that as an exercise for the reader. 😉
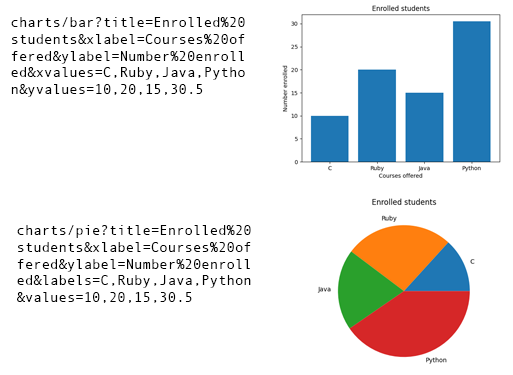
The following code defines the pie chart endpoint and schema:
class PieChartParams(Schema):
title = String(required=False, validate=Length(0, 30))
values = DelimitedList(Number, required=True)
labels = DelimitedList(String)
@app.get("/charts/pie")
@app.input(PieChartParams, location="query")
def pie_chart(data: dict):
fig = Figure()
axes: Axes = fig.subplots(squeeze=False)[0][0]
axes.pie(data["values"], labels=data.get("labels"))
axes.set_title(data.get("title"))
buf = BytesIO()
fig.savefig(buf, format="png")
buf.seek(0)
return send_file(buf, download_name="chart.png", mimetype="image/png")
Using property-based testing
I like all my code to be fully tested, or at least, "fully" to my knowledge. I started off writing standard pytest unit tests for the endpoint (with much thanks to Github Copilot for filling in the tests). But I wasn't sure whether there were edge cases that I was missing, since my code wraps on top of matplotlib and I'm not a matplotlib expert.
What I wanted was property-based testing: automatically generated tests based on function parameter types, which make sure to include commonly missed edge cases (like negative numbers). In the past, I've used the hypothesis library for property-based testing. I wondered if there was a variant that was specially built for API frameworks, where the parameter types are declared in schemas, and lo-and-hold, I discovered that exact creature: schemathesis. It's built on top of hypothesis, and is perfect for FastAPI, APIFlask, or any similar framework.
The schemathesis library can be used from the command-line or inside pytest, using a fixture. I opted for the latter since I was already using pytest, and after reading their WSGI support docs, I came up with this file:
import pytest
import schemathesis
import hypothesis
from src import app
schema = schemathesis.from_wsgi("/openapi.json", app)
@schema.parametrize()
@hypothesis.settings(print_blob=True, report_multiple_bugs=False)
@pytest.mark.filterwarnings("ignore:Glyph:UserWarning")
def test_api(case):
response = case.call_wsgi()
case.validate_response(response)
There are a few additional lines in that file that you may not need: the hypothesis.settings fixture, and the pytest.mark.filterwarnings fixture. I added settings to increase the verbosity of the output, to help me replicate the issues, and I added filterwarnings to ignore the many glyph-related warnings coming out of matplotlib.
The API improvements
As a result of the schemathesis tests, I identified several parameters that could use additional validation.
I added both a min and max to the Number field in the values parameter:
values = DelimitedList(Number(validate=Range(min=0, max=3.4028235e38)), required=True)
I also added a custom validator for situations which couldn't be addressed with the built-in validators. The custom validator checks to make sure that the number of labels matches the number of values provided, and disallows a single value of 0.
@validates_schema
def validate_numbers(self, data, **kwargs):
if "labels" in data and len(data["labels"]) != len(data["values"]):
raise ValidationError("Labels must be specified for each value")
if len(data["values"]) == 1 and data["values"][0] == 0:
raise ValidationError("Cannot create a pie chart with single value of 0")
The full code can be seen in __init__.py.
I added specific tests for the custom validators to my unit tests, but I didn't do so for the built-in min/max validators, since I'm relying on the library's tests to ensure those work as expected.
Thanks to the property-based tests, users of this API will see a useful error instead of a 500 error. I'm a fan of property-based testing, and I hope to find ways to use it in future applications.