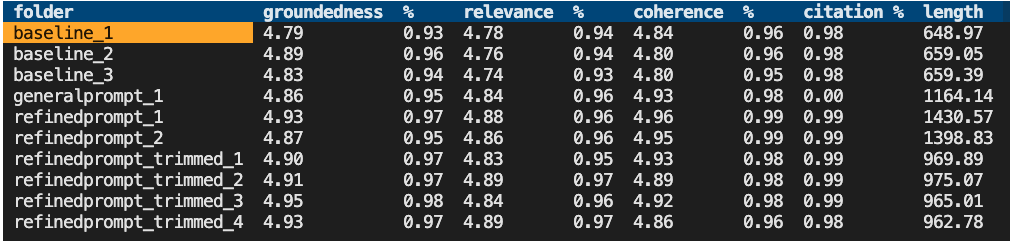
In this post, I'll share a fairly easy way to convert HTML pages to PDF files using the Playwright E2E testing library.
Background: I am working on a RAG chat app solution that has a PDF ingestion pipeline. For a conference demo, I needed it to ingest HTML webpages instead. I could have written my own HTML parser or tried to integrate the LlamaIndex reader, but since I was pressed for time, I decided to just convert the webpages to PDF.
My first idea was to use dedicated PDF export libraries like pdfkit and wkhtml2pdf but kept running into issues trying to get them working. But then I discovered that my new favorite package for E2E testing, Playwright, has a PDF saving function. 🎉 Here’s my setup for conversion.
Step 1: Prepare a list of URLs
For this script, I use the requests package to fetch the HTML for the main page of the website. Then I use the BeautifulSoup scraping library to grab all the links from the table of contents. I process each URL, turning it back into an absolute URL, and add it to the list.
urls = set()
response = requests.get(url, timeout=10)
soup = BeautifulSoup(response.text, "html.parser")
links = soup.find("section", {"id": "flask-sqlalchemy"}).find_all("a")
for link in links:
if "href" not in link.attrs:
continue
# strip off the hash and add back the domain
link_url = link["href"].split("#")[0]
if not link_url.startswith("https://"):
link_url = url + link_url
if link_url not in urls:
urls.add(link_url)
Save each URL as PDF
For this script, I import the asynchronous version of the Playwright library. That allows my script to support concurrency when processing the list of URLs, which can speed up the conversion.
from playwright.async_api import BrowserContext, async_playwrightThen I define a function to save a single URL as a PDF. It uses Playwright to goto() the URL, decides on an appropriate filename for that URL, and saves the file with a call to pdf().
async def convert_to_pdf(context: BrowserContext, url: str):
try:
page = await context.new_page()
await page.goto(url)
filename = url.split("https://flask-sqlalchemy.palletsprojects.com/en/3.1.x/")[1].replace("/", "_") + ".pdf"
filepath = "pdfs/" / Path(filename)
await page.pdf(path=filepath)
except Exception as e:
logging.error(f"An error occurred while converting {url} to PDF: {e}")Next I define a function to process the whole list. It starts up a new Playwright browser process, creates an asyncio.TaskGroup() (new in 3.11), and adds a task to convert each URL using the first function.
async def convert_many_to_pdf():
async with async_playwright() as playwright:
chromium = playwright.chromium
browser = await chromium.launch()
context = await browser.new_context()
urls = []
with open("urls.txt") as file:
urls = [line.strip() for line in file]
async with asyncio.TaskGroup() as task_group:
for url in urls:
task_group.create_task(convert_to_pdf(context, url))
await browser.close()
Finally, I call that convert-many-to-pdf function using asyncio.run():
asyncio.run(convert_many_to_pdf())Considerations
Here are some things to think about when using this approach:
- How will you get all the URLs for the website, while avoiding external URLs? A sitemap.xml would be an ideal way, but not all websites create those.
- Whats an appropriate filename for a URL? I wanted filenames that I could convert back to URLs later, so I converted / to _ but that only worked because those URLs had no underscores in them.
- Do you want to visit the webpage at full screen or mobile sized? Playwright can open at any resolution, and you might want to convert the mobile version of your site for whatever reason.