Ollama is a tool that makes it easy to run small language models (SLMs) locally on your own machine - Mac, Windows, or Linux - regardless of whether you have a powerful GPU. It builds on top of llama.cpp, which uses various techniques to be able to run language models on a CPU, whether it's ARM or AMD.
I am excited about Ollama because it empowers anyone to start experimenting with language models, and because it gives me an easy way to see how the SLMs compare to the LLMs that I typically use (GPT 3.5, GPT 4).
As you know if you've read my blog, I spend much of my time these days on building applications using RAG (Retrieval Augmented Generation), a technique that gets an LLM to answer questions accurately for a domain.
A simple RAG flow can be visualized by this diagram:
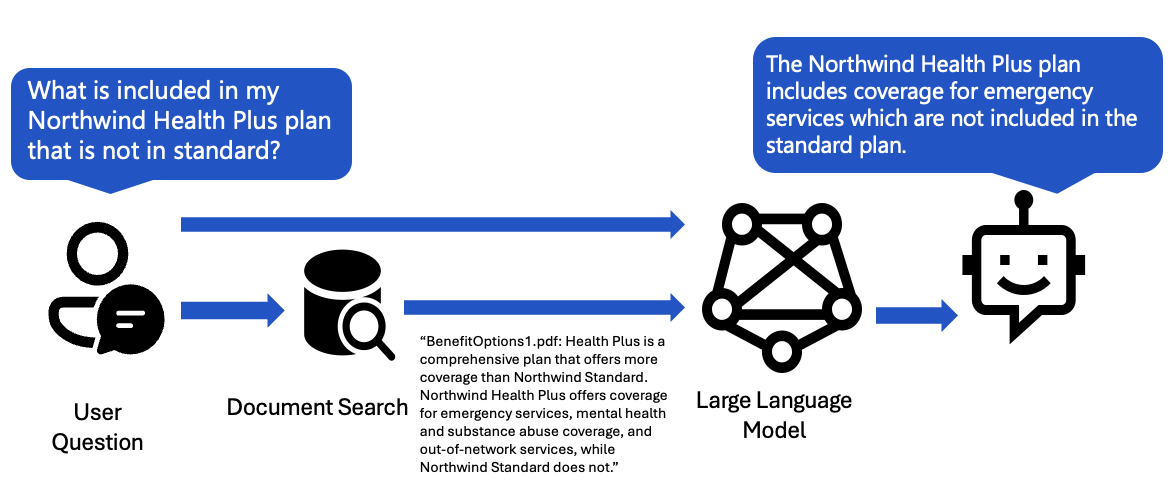
We take the user question, use it to search the database, then send the results to the LLM to answer.
I've been on a quest to figure out how to make my RAG applications compatible with Ollama SLMs, and I've finally got the components working well enough together in our RAG on PostgreSQL solution.
Challenge #1: Citation format
In our system message, we demand that the LLM stick to the sources, and that it provides citations in a particular format:
Each product has an ID in brackets followed by colon and the product details. Always include the product ID for each product you use in the response. Use square brackets to reference the source, for example [52]. Don't combine citations, list each product separately, for example [27][51].
The citation format is important, so that the frontend can renders the citations as footnotes.
When I first started testing out SLMs, I was immediately disheartened by the results, as they wouldn't adhere to my instructions. For example, given that system message, the llama2:7b model generated answers like:
The Trekker Clear Hiking Shoes from WildRunner are designed for the adventurous hiker who seeks both comfort and durability. The transparent shoes feature a waterproof and breathable upper fabric, a rugged carbon-infused sole for excellent traction, and a shock-absorbing midsole for enhanced comfort on long hikes.
Notice: no citations! Not even an attempt at brackets. Fortunately, llama 3.1L8B came out last week, and it reliably generates citations in the correct format:
The Trekker Clear Hiking Shoes from WildRunner are designed for comfort and durability [41]. They have a transparent upper fabric, which is waterproof and breathable, allowing for airflow while keeping feet dry on long hikes. The shoe also features a rugged carbon-infused sole for excellent traction and a shock-absorbing midsole for enhanced comfort.
See that citation in brackets at the end of the first sentence? Now our frontend can reliably connect the citations to the data sources, and render more source details to the user.

Challenge #2: Vector embeddings
When we search the database using the user query, the best practice is to use a hybrid search, a combination of vector search plus full-text search. For a PostgreSQL database, we can achieve a hybrid search using the built-in full text search feature plus the pgvector extension.
In order to do that vector search, we first need to use an embedding model to compute the vector embeddings for each row of the database. In production, I use an OpenAI embedding model. With Ollama, there are several embedding models available, plus an OpenAI-compatible embeddings endpoint.
To make it easy for me to switch between OpenAI and Ollama, I made separate columns for each model in my schema:
embedding_ada002: Mapped[Vector] = mapped_column(Vector(1536)) # ada-002
embedding_nomic: Mapped[Vector] = mapped_column(Vector(768)) # nomic-embed-text
Then I made the embedding column into an environment variable, so that I could set it alongside my selection of models, and all my code updates and queries the right embedding column. Here's the updated vector search SQL query:
vector_query = f"""
SELECT id, RANK () OVER (ORDER BY {self.embedding_column} <=> :embedding) AS rank
FROM items
{filter_clause_where}
ORDER BY {self.embedding_column} <=> :embedding
LIMIT 20
"""Finally, I updated my local seed data with the embedding_nomic column, so that I could start running queries on the local data immediately.
Challenge #3: Function calling
Earlier I showed a diagram of a simple RAG flow. That's great for a start, but for a production-level RAG, we need a more advanced RAG flow, like this one:

We take the user question, send it to an LLM in a query rewriting step, use the LLM-suggested query to search the knowledge base, and then send the results to the LLM to answer. This query rewriting step brings multiple benefits:
- If the user's query references a topic earlier in the conversation (like "and what other options are there?"), the LLM can fill in the missing context (turning it into a search query like "other shoe options").
- If the user's query has spelling errors or is written in a different language, the LLM can clean up the spelling and translate it.
- We can use that step to figure out metadata for searching as well. For the RAG on PostgreSQL, we also ask the LLM to suggest filters for the
priceorbrandcolumns, to better answer questions like "get me shoes cheaper than $30".
For best results, we use the OpenAI function calling feature to give us more structured retrieval. OpenAI also just announced an overlapping feature, Structured Outputs, but that's newer and less widely supported.
Fortunately, Ollama just added support for OpenAI function calling, available for a handful of models, including my new favorite, llama3.1.
But when I first tried my function calls with llama3.1, I got poor results: it worked fine for the most basic function call with a single argument, but completely made up the arguments for any fancier function calls. When I shared my llama3.1 vs. gpt-35-turbo comparison with others, I was told to try providing few shot examples. That same week, Langchain put out a blog post about using few shot examples to improve function calling performance.
So I made several few shot examples, like:
{
"role": "user",
"content": "are there any shoes less than $50?"
},
{
"role": "assistant",
"tool_calls": [
{
"id": "call_abc456",
"type": "function",
"function": {
"arguments": "{\"search_query\":\"shoes\",\"price_filter\":{\"comparison_operator\":\"<\",\"value\":50}}",
"name": "search_database"
}
}
]
},
{
"role": "tool",
"tool_call_id": "call_abc456",
"content": "Search results for shoes cheaper than 50: ..."
}
And it worked! Now, when I use Ollama with llama3.1 for the query rewriting flow, it gives back function arguments that match the function schema.
Challenge #4: Token counting
Our frontend allows the users to have long conversations, so that they can keep asking more questions about the same topic. We send the conversation history to the LLM, so it can see previously discussed topics. But what happens if a conversation is too long for the context window of an LLM?
In our solution, our approach is to truncate the conversation history, dropping the older messages that don't fit. In order to that, we need to accurately count the tokens for each message. For OpenAI models, we can use the tiktoken package for token counting, which brings in the necessary token model for the model used. I've built a openai-messages-token-helper package on top of tiktoken that provides convenience functions for token counting and conversation truncation.
Here's the problem: each model has their own tokenization approach, and the SLMs don't use the same tokenizer as the OpenAI embedding models. So, if we use tiktoken to calculate the token counts, our counts may be very off, and we may accidentally send a sequence of messages that exceeds the context window of the SLM. We have two options:
- SLM tokenizers: It should be possible to bring in tokenizers for many/all of the SLMs via the HuggingFace tokenizers class. I have not done it myself, but I've seen it implemented in litellm and elsewhere.
- Accept the inaccuracy: We can use the OpenAI tokenizer, assuming it's close to correct, and expect to see a few errors around context windows being exceeded.
For now, I am going with approach #2, since my primary use of Ollama is local development and teaching situations. If I was going to use Ollama in a production scenario, I would go for approach #1 and go through the effort of bringing in the SLM's tokenizer. Instead, I log out a warning to the terminal so that the developer is aware that we're not using the correct tokenizer, and that has been fine for development so far.
All together now
All those pieces are implemented in rag-postgres-openai-python, and you can try it out today in GitHub Codespaces, as long as you have a GitHub account and sufficient Codespaces quota. The Ollama feature does require a larger Codespace than usual, since LLMs require more memory, so you may find that it uses up your quota faster than typical Codespace usage. You can also use it locally, with an Ollama running on your machine. Give it a go, and let me know in the issue tracker if you encounter any issues! Also, if you have ported other RAG solutions to Ollama, please share your challenges and solutions. Happy llama'ing!
No comments:
Post a Comment